The main sell of AWS Lambda (and Functions as as Service in general) is the ability to shift developer attention away from infrastructure to the business logic. Nonetheless, there are a number of cross-cutting concerns that Lambdas need to handle. This post outlines some of these and how they can be addressed.
Note, this focuses on the Node.js runtime, but the same principles can be applied to others.
As every Lambda function is automatically set up with a AWS CloudWatch Log group, debugging can be as simple as adding a console.log. This can often be enough for simpler cases, but as projects grow, so does the need for logs. Perhaps your system is composed of multiple Lambdas and you need to search across them, or you need to run aggregations. Whilst this can be solved with regexs, writing logs in a machine-readable format such as JSON simplifies parsing and querying.
Pino is a lightweight structured logging library that works well with Lambda. Using its base option, we can decorate all log lines with the Lambda’s runtime context:
const pino = require('pino')
const logger = pino({
base: {
memorySize: process.env.AWS_LAMBDA_FUNCTION_MEMORY_SIZE,
region: process.env.AWS_REGION,
runtime: process.env.AWS_EXECUTION_ENV,
version: process.env.AWS_LAMBDA_FUNCTION_VERSION,
},
name: process.env.AWS_LAMBDA_FUNCTION_NAME,
level: process.env.LOG_LEVEL || 'info',
useLevelLabels: true,
})
exports.handler = () => {
logger.info({ uuid: 'foo' }, 'hello world')
}
Results in logs such as:
{
"level": "info",
"memorySize": "128",
"msg": "hello world",
"name": "my-lambda",
"region": "eu-west-2",
"runtime": "AWS_Lambda_nodejs12.x",
"time": 1493426328206,
"uuid": "foo",
"v": 1,
"version": "$LATEST"
}
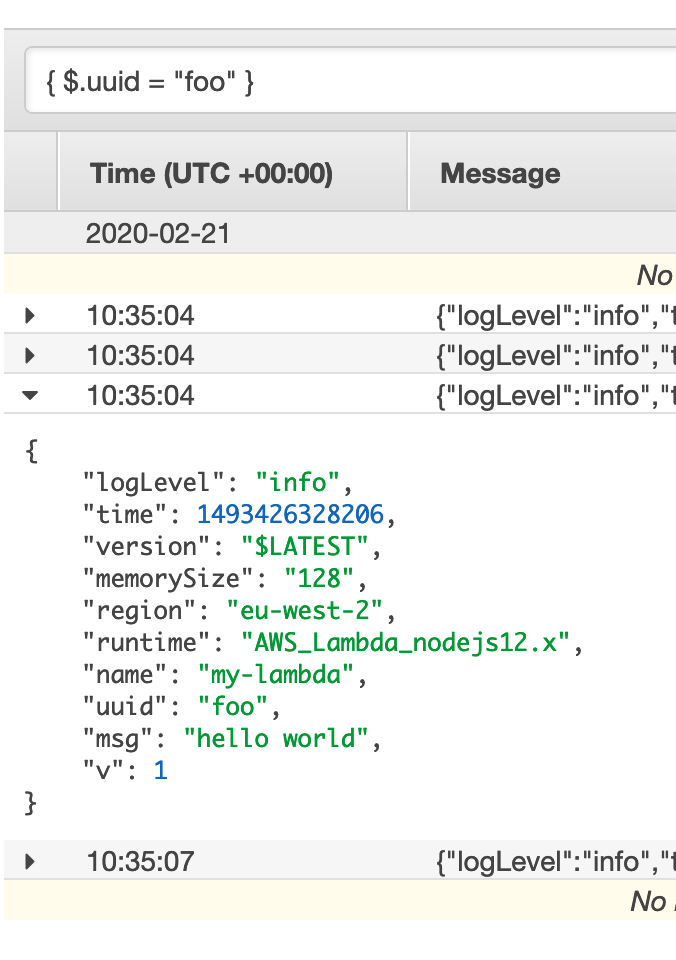
CloudWatch Logs has first-party support for JSON filters. For example, to filter log lines containing the foo UUID, use { $.uuid = "foo" }:
As a distributed system grows, debugging becomes harder. Microservice and serverless architectures are composed of many services interacting with each other. When there’s a problem, it can be difficult to identify which service in the mesh is at fault.
Yan Cui’s Capture and forward correlation IDs through different Lambda event sources outlines how correlation IDs can be used to alleviate this. In the same way as identifiers such as a uuid can be logged to provide context, other identifiers can be used to thread messages together as they flow through the system.
AWS Lambda includes awsRequestId in its context object, which is unique per invocation. When set up as a integration in API Gateway, this provides a way to trace a request back its initial API call. However, this ID is not automatically forwarded to further downstream services e.g. other AWS services or third-party APIs.
AWS X-Ray is a fully-featured tracing system that provides this functionality out of the box. In automatic mode (the default), all outgoing HTTP(S) requests can be instrumented using the captureHTTPsGlobal method:
const https = require('https')
const AWSXRay = require('aws-xray-sdk-core')
exports.handler = async () => {
AWSXRay.captureHTTPsGlobal(https)
await got('https://tlvince.com')
}
Note, this works by monkey patching the core Node.js http/https modules, which can be dangerous. Alternatively, X-Ray’s scope can be reduced to AWS calls using the captureAWS method.
For completeness, we can also add the X-Ray trace ID as well as the awsRequestId to the logs for easier cross-referencing. One gotcha to remember is neither IDs are set until the function has been executed, so will be undefined if referenced in the function’s global context rather than inside its handler. To workaround this, use a Pino child logger:
const https = require('https')
const got = require('got')
const pino = require('pino')
const AWSXRay = require('aws-xray-sdk-core')
const parentLogger = pino({
base: {
memorySize: process.env.AWS_LAMBDA_FUNCTION_MEMORY_SIZE,
region: process.env.AWS_REGION,
runtime: process.env.AWS_EXECUTION_ENV,
version: process.env.AWS_LAMBDA_FUNCTION_VERSION,
},
name: process.env.AWS_LAMBDA_FUNCTION_NAME,
level: process.env.LOG_LEVEL || 'info',
useLevelLabels: true,
})
exports.handler = (event, context) => {
AWSXRay.captureHTTPsGlobal(https)
const logger = parentLogger.child({
traceId: process.env._X_AMZN_TRACE_ID,
awsRequestId: context.awsRequestId,
})
logger.info({ uuid: 'foo' }, 'hello world')
}
Probably the most important technical concern for any externally-facing service is to validate its inputs. Doing this upfront helps guard against malformed (or malicious) events, helps simplify property references within the business logic and can also help reduce costs by short-circuiting the function early.
Depending on your needs, a JSON schema validator such as ajv is typically the go-to option. validate is a lightweight alternative, which trades expressiveness at the expense of schema interoperability.
An example for SQS events:
const Schema = require('validate')
const schema = new Schema({
Records: [
{
body: {
type: String,
required: true,
},
},
],
})
exports.handler = event => {
const errors = schema.validate(event, { strip: false })
if (errors.length) {
throw new Error(error)
}
}
Note, { strip: false } is used to ensure validate does not mutate the event object.
In the same manner as input event validation, environment variables can be validated via a simple process.env check:
const requiredEnvs = ['FOO']
const missingEnvs = requiredEnvs.filter(requiredEnv => !process.env[requiredEnv])
if (missingEnvs.length) {
throw new Error(`missing environment variables ${missingEnvs}`)
}
A neat performance optimisation I learnt from Matt Lavin’s Node Summit 2018 talk was that HTTP connections can be reused. By default, Node.js’s HTTP agent does not use keep-alive and therefore every request incurs the overheads of establishing a new TCP connection.
Since the majority of HTTP requests made by Lambdas are to other AWS services, it makes sense to scope this optimisation first and observe its effect:
const AWS = require('aws-sdk')
const https = require('https')
const agent = new https.Agent({
keepAlive: true,
})
AWS.config.update({
httpOptions: {
agent,
},
})
Since aws-sdk 2.463.0, this is further simplified by setting the AWS_NODEJS_CONNECTION_REUSE_ENABLED environment variable. The configuration can therefore be removed from the handler and moved to your infrastructure as code tool of choice.
Each of these concerns can be combined together into a re-usable decorator function. For example:
const https = require('https')
const pino = require('pino')
const Schema = require('validate')
const AWSXRay = require('aws-xray-sdk-core')
const parentLogger = pino({
base: {
memorySize: process.env.AWS_LAMBDA_FUNCTION_MEMORY_SIZE,
region: process.env.AWS_REGION,
runtime: process.env.AWS_EXECUTION_ENV,
version: process.env.AWS_LAMBDA_FUNCTION_VERSION,
},
name: process.env.AWS_LAMBDA_FUNCTION_NAME,
level: process.env.LOG_LEVEL || 'info',
useLevelLabels: true,
})
module.exports = ({ handler, requiredEnvs = [], eventSchema = {} }) => (
event,
context
) => {
AWSXRay.captureHTTPsGlobal(https)
const logger = parentLogger.child({
traceId: process.env._X_AMZN_TRACE_ID,
awsRequestId: context.awsRequestId,
})
const schema = new Schema(eventSchema)
const errors = schema.validate(event, { strip: false })
if (errors.length) {
logger.debug({ errors }, 'event validation errors')
throw new Error(errors)
}
const missingEnvs = requiredEnvs.filter(
requiredEnv => !process.env[requiredEnv]
)
if (missingEnvs.length) {
logger.debug({ missingEnvs }, 'missing environment variables')
throw new Error(`missing environment variables ${missingEnvs}`)
}
return handler(event, context, { logger })
}
The Lambda handler body itself can then be simplified to focussing on the business logic, besides a few lines of configuration:
const decoratedHandler = require('./handler-decorator')
const handler = async (event, context, { logger }) => {
logger.debug('reached Lambda handler')
return event.Records.map(record => record.body)
}
exports.handler = decoratedHandler({
handler,
requiredEnvs: ['FOO'],
eventSchema: {
Records: [
{
body: {
type: String,
required: true,
},
},
],
},
})
By extracting noisy yet necessary boilerplate, Lambda handlers can be kept lean and focussed on their business logic. A number of cross-cutting concerns were discussed, with an approach to encapsulate them using a reusable function following the decorator pattern. Alternatives include middy, a more pluggable, middleware-based approach or lambda_decorators for the Python runtime.