Want to read online content on your Kindle without all the clutter? Looking for a command-line based alternative to web services like Instapaper and Klip.me? Read on.
Reading using the Kindle is great. Reading via a web browser is often not.
Websites like Instapaper et al. are one way of bridging the gap. Instapaper
in particular provides a very fluid and easy to use service: add some articles
to your reading list, grant it access to your @free.kindle.com address and
watch in amazement as they show up on your Kindle, bundled as a newspaper-like
eBook, delivered daily.
It’s a great service but I wanted to see if I could build my own. I also noticed Instapaper’s text view did not work on all sites (notably Hacker News comments), was weary of handing over my reading habits to yet another third party and mostly, wanted more control over how the eBook was made.
Enter Periodical.
Periodical builds on these ideas and implements them as a simple command line tool. Pass it some URLs as position parameters and it’ll generate a nicely formatted eBook, ready to be copied onto your Kindle.
At its core, Periodical is a Python (2)-based script. After parsing the command
line arguments, URLs are sent to a content extractor. Their resulting HTML is
formatted and structured within a file-based document hierarchy. The final eBook
is then generated as a mobi file.
Web page content extraction is a hard problem. Due to the vastly heterogeneous nature of the web, it is nigh on impossible to achieve 100% accurate results. In an earlier guise, Periodical used a bespoke content extraction library from another project (still in “stealth mode”). Despite various heuristics, classification and weighted tree based approaches, it is difficult to generalise an algorithm that’s consistent for all web pages. I highly recommend reading Tomaz Kovacic’s research on text extraction for further insight.
Opting for accuracy over simplicity, Periodical uses the excellent boilerpipe library for content extraction. Since boilerpipe is Java based, a Python binding — python-boilerpipe (powered by JPype) — mitigates the need for calling boilerpipe as a sub-process.
Minimal formatting to boilerpipe’s output (namely reintroducing the title tag
and specifying UTF8 encoding; mandatory for the Kindle) is applied via
Beautiful Soup, written as a kindlerb document tree and passed to
Amazon’s kindlegen to generate the resulting mobi file.
Periodical works well as a convenient and extensible command-line tool, with high extraction accuracy thanks to boilerpipe (~99% median F1 score). However, there’s still room for improvement in the script itself.
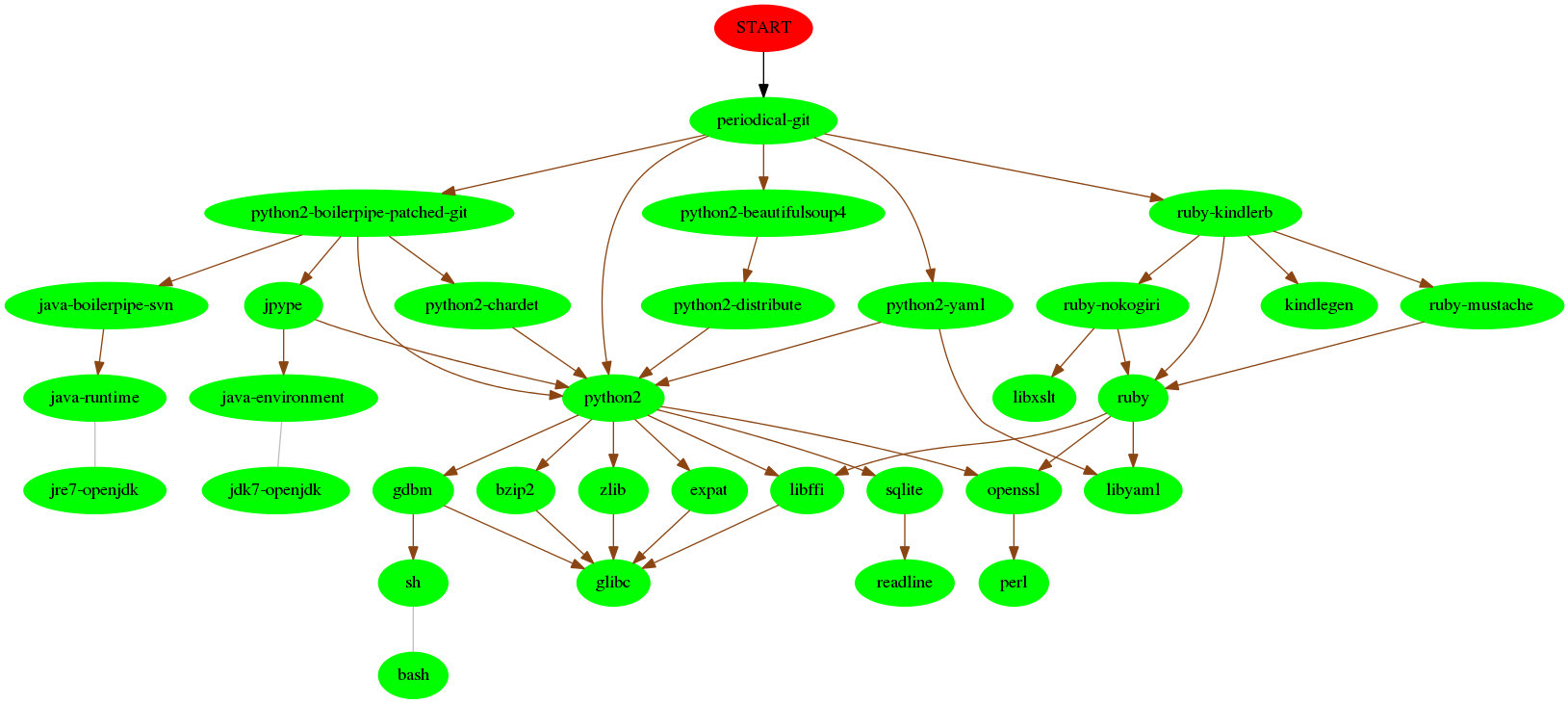
First, Periodical is suffering in dependency hell (see the
dependency tree) by spanning three programming languages (Python,
Java, Ruby) and pulling in a raft of libraries. The first point of call would be
to port kindlerb to Python.
Second, the reintroduction of the title tag is very naive, simply using the
content of the first h1 tag or falling back to the URL’s hostname. A closer
look at the boilerpipe API may reveal a more robust method, which in turn will
need including in python-boilerpipe.
{kind=link}