When provisioning a Lambda function with Terraform, one gotcha to remember is that Terraform expects the deployment package to exist before it can create the function itself. Put another way, the infrastructure code depends on the application code.
One way of handling this is to manage both the function logic and its provisioning in Terraform using a local file deployment package:
This ensures Terraform can build out its dependency graph correctly and so can create the deployment package before the function.
However, there are a number of downsides to this approach. Firstly, as the docs mention, Terraform is unoptimised for handling large file uploads. It does not handle multi-part or resuming.
Secondly, because source_code_hash is a computed property (its value isn’t known until terraform apply is ran), Terraform is often overly-cautious in deciding when the deployment package has changed. More often than not, this results in Terraform creating a new version (and therefore reuploading the deployment package) on every run.
Another approach is to decouple infrastructure from application code. In this approach, Terraform creates a placeholder deployment package to fulfil its dependency requirement and the deployment of the real application code is managed outside of Terraform, ideally in its own automation step:
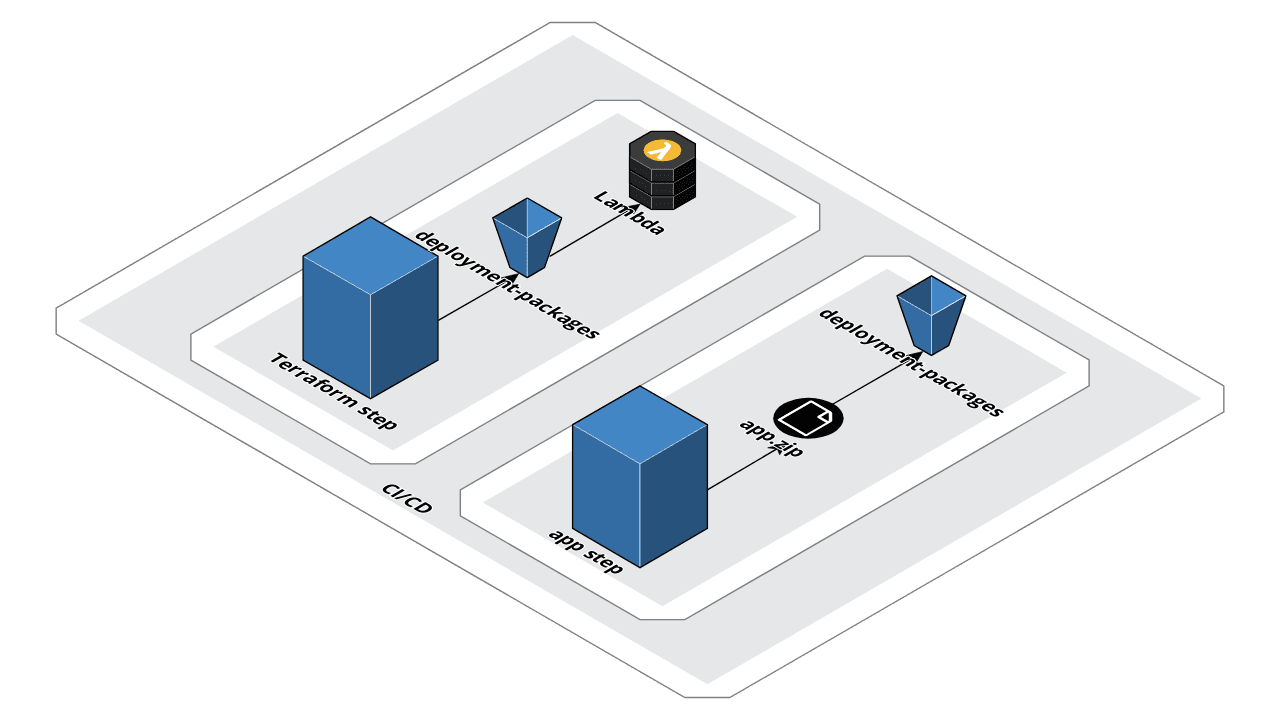
An implementation of this (in Terraform 0.12.x) uses the archive_file provider along with the s3_key and s3_bucket attributes in the Lambda resource:
data "archive_file" "my_lambda_placeholder_zip" {
type = "zip"
output_path = "${path.module}/lambda/my_lambda.zip"
source {
content = "exports.handler = () => {}"
filename = "index.js"
}
}
resource "aws_s3_bucket_object" "my_lambda" {
bucket = aws_s3_bucket.deployment.id
key = "lambda/connection-manager.zip"
source = data.archive_file.core_placeholder_zip.output_path
}
resource "aws_lambda_function" "my_lambda" {
function_name = "my-lambda"
description = "Decoupled Lambda deployment example"
s3_bucket = aws_s3_bucket.deployment.id
s3_key = aws_s3_bucket_object.my_lambda.id
handler = "index.handler"
runtime = "nodejs12.x"
}
The application deployment step is then a few lines of shell:
#!/bin/sh
cd /path/to/my-lambda
npm run build
cd dist
zip -9rX "my-lambda.zip" .
aws lambda update-function-code \
--function-name "my-lambda" \
--zip-file "fileb://dist/my-lambda.zip"
By decoupling infrastructure from application provisioning in Terraform, we trade managing part of the stack outside of Terraform with the ability to optimise the deployment of application code. Issues surrounding change detection on often large deployment artefacts are resolved and uploads are more efficiently handled by the AWS CLI.
Typically a function’s configuration and dependant infrastructure changes less than application logic itself. By decoupling the two, the risk of failure between infrastructure changesets is reduced.